在container內部,有時候需要跑多個程式,但每個程式環境不一樣的話,有以下幾種方法,那我自己如果只是測試某個程式,我會用venv的方式來做,就可以用上一篇教的,開一個新的window,activate venv的環境,如果是一個新的專案,那我會選擇再起一個container做研發,比較不會搞錯。
今天來介紹一個python套件的安裝器,名稱為uv,不僅安裝方式簡單,在下載python package的速度也蠻快的,不過有些比較冷門的package時會有卡住的問題甚至不支援,不過還是推薦大家使用。
安裝透過pip,下載package的方式只是前面多個uv,如果你想下載到本地環境而不是虛擬環境,可以在後面多加system
pip install uv
uv venv
source .venv/bin/activate
uv pip install <package>
# 下載到本地的環境
uv pip install <package> --system
今天另一個主題是爬蟲,我自己認為爬蟲是每個AI工程師都加減要會的技能,畢竟有些資料是公開資料集沒有的,還是要自己去蒐集資料整理過濾,我自己再做一些專案的時候甚至連公開資料集都沒有,所以爬蟲就對我佔了一席之地。
爬蟲有很多種:
基本上scrapy在爬靜態網站效率上蠻好的,如果要用在動態網頁,需要使用一些其他的package來輔助,而且寫的code並不是python,相對起來會比較麻煩。
那BeautifulSoup我自己會拿來爬一些簡單的網站,一些分析找到對應的資料做爬取。
那selenium蠻常會用在登入 按鈕 滾動等等,不過速度上就比較慢一點。
今天主要教的網址是最近我有在爬的: https://www.hakkaradio.org.tw/
如果要爬的話,可以把sleep time設高一點,不要讓別人以為你在攻擊他,而封鎖你的ip,當個螞蟻慢慢爬就好。
我的目標是要爬取音檔,所以先分析音檔在哪裡,然後依序去看網站是如何把音檔都給你的
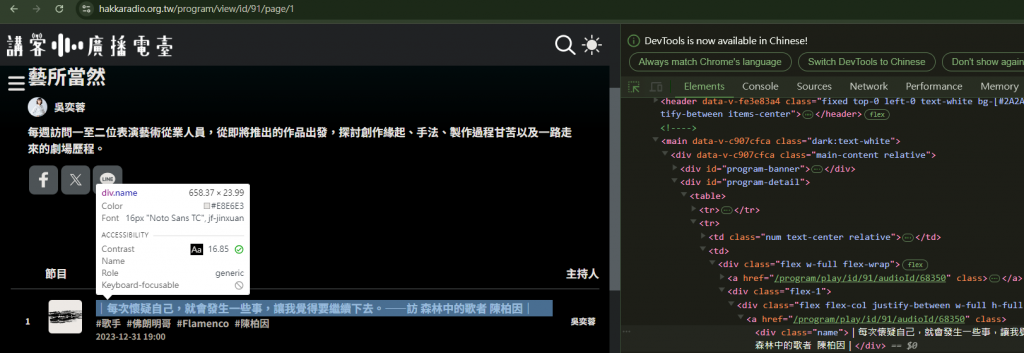
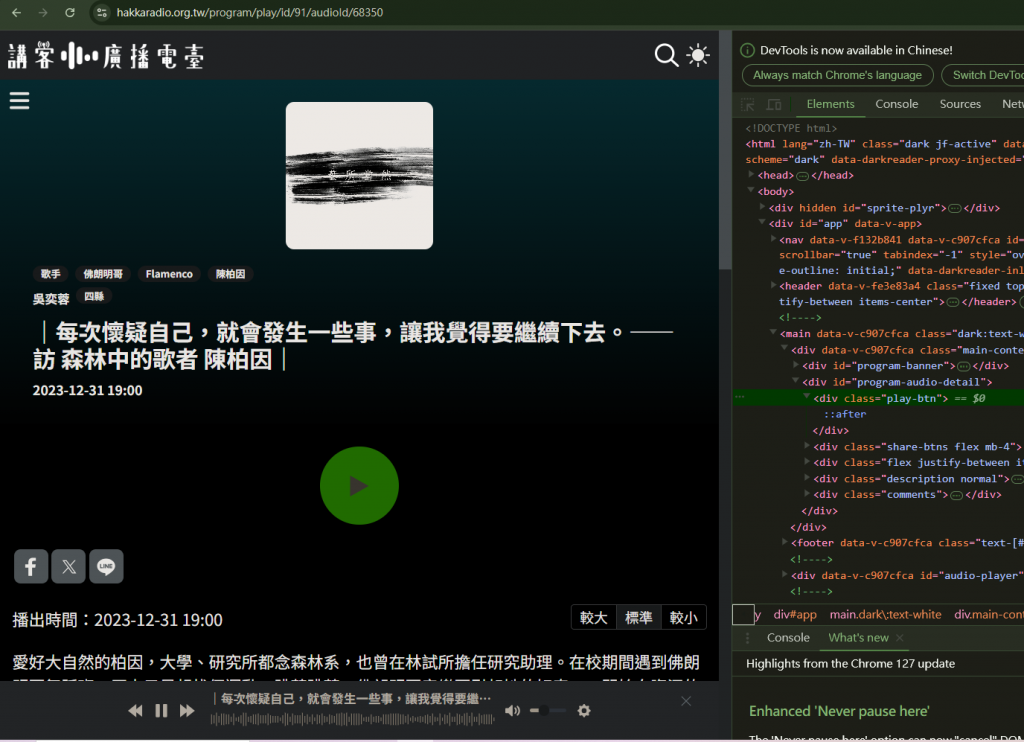
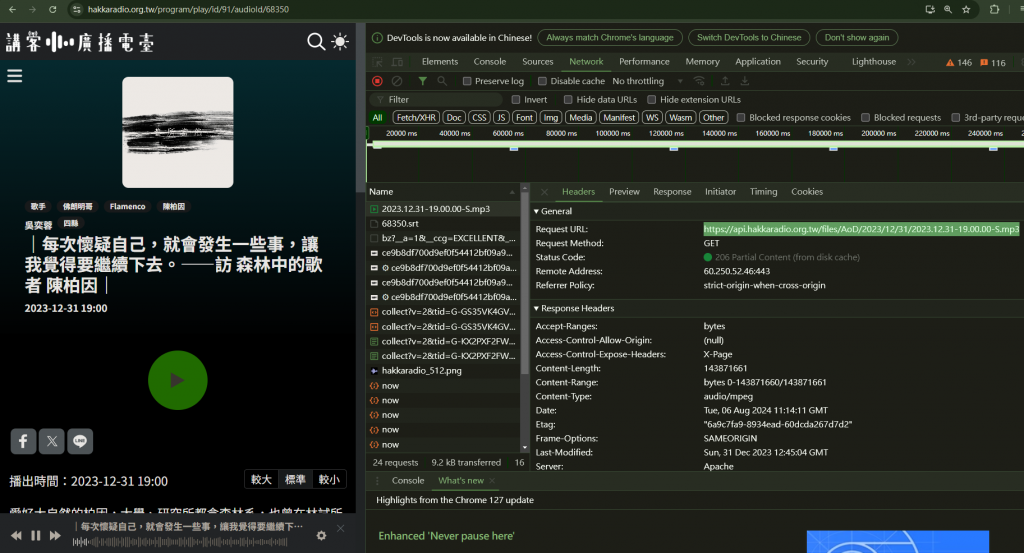
目前只是分析網站如何把mp3丟給你的,再來我們將透過python寫爬蟲,將這些節目爬下來。
今天先更新到這~~


 iThome鐵人賽
iThome鐵人賽